Fraction AI: Pioneering Annotated Data Solutions through Blockchain
28 July 2024•
%2Fuploads%2Finnovations-blockchain%2Fspotlights%2Ffraction%2Fcover.jpg&w=3840&q=75)
%2Fuploads%2Finnovations-blockchain%2Fspotlights%2Ffraction%2Flogo.jpg&w=3840&q=75)
ChatGPT’s debut on November 30, 2022, marked a pivotal moment that captivated audiences worldwide. However, its emergence was neither sudden nor isolated. Instead, it represents the culmination of decades of collaborative efforts by thousands of AI researchers across the globe.
The roots of ChatGPT trace back to the concept of Deep Learning, which originated in the 1950s. Despite its early inception, Deep Learning remained relatively obscure until 2012, when AlexNet’s resounding victory in the Imagenet Challenge brought it to the forefront. The subsequent introduction of the Transformer architecture by Google in 2017, along with innovations such as Foundation models and advancements in transfer learning, paved the way for developing ChatGPT into the sophisticated platform it is today.
Transformer Architecture: Neural network design introduced by Vaswani et al. in 2017. It relies on self-attention mechanisms to process input data in parallel, making it highly efficient for tasks like natural language processing and sequence modeling. Unlike traditional recurrent neural networks (RNNs), Transformers do not require sequential processing, which allows for greater scalability and improved performance on large datasets.
Foundation Models: Large-scale, pre-trained machine learning models designed to serve as a versatile base for a wide range of tasks. These models are trained on vast and diverse datasets, capturing general features and patterns. Once pretrained, they can be fine-tuned for specific applications, such as language translation or image recognition, with relatively little additional data, making them highly adaptable and efficient.
Transfer Learning: Machine learning technique where a model developed for one task is reused as the starting point for a model on a second, related task. This approach leverages pre-trained models to improve learning efficiency and performance on new tasks, especially when data for the new task is limited. Transfer learning is particularly effective in scenarios where computational resources or labeled data are scarce.
Early Discoveries: Shashank Yadav’s AI journey and the spark for Fraction AI
 Photo: Shashank Yadav, Co-founder of Fraction AI.
Photo: Shashank Yadav, Co-founder of Fraction AI.
Shashank Yadav’s career in artificial intelligence began during his sophomore year at IIT Delhi in 2014, when his curiosity was piqued by a project aimed at identifying brain tumors from MRI scans using Machine Learning. What initially started as a casual exploration quickly evolved into a deep-seated passion and a professional pathway in machine learning. This early experience led him to join the Vision lab at IIT, where he tackled the formidable challenge of developing self-driving car technology using only a single camera—a problem that continues to engage some of the brightest minds in the field, with the teams at Tesla leading the pack.
After completing his studies, Shashank took on a role as a Machine Learning Researcher at Goldman Sachs within their Core AI Team. His journey in AI research continued as he became a Founding Research Scientist at an early-stage startup, and later, a researcher for a hedge fund. Across these positions, he had the opportunity to deploy numerous AI models in various corporate environments. Each time, the most significant challenge was not a shortage of GPUs, training platforms, or deployment solutions—all of which were readily available. Instead, the real hurdle was consistently finding high-quality annotated data at scale.
Annotated data challenges: Paving the way for Fraction AI
Annotated or labeled data is the critical fuel for machine learning algorithms, much like gasoline powers a car. For example, to teach an AI to generate an image of a cat with specific characteristics, it requires a dataset of cat images each annotated with details like fur color, size, and breed. This process enables the AI to differentiate and recognize various cat types accurately. However, the quality of the input data directly impacts the efficacy of the AI, adhering to the principle known as “Garbage In, Garbage Out.” This principle asserts that poor-quality training data will inevitably produce inferior AI models.
Despite the essential role of high-quality labeled data, the current landscape for acquiring such data is fraught with challenges. Many companies that provide labeled data operate on closed, proprietary platforms, which complicates the verification of data quality. Additionally, the reliance on a limited pool of contractors for data labeling introduces potential biases.
This labeling process is not only time-consuming, as it is typically performed reactively upon specific requests, but also costly, rendering it inaccessible to smaller entities and perpetuating reliance on major tech companies who dominate the data access.
These pervasive challenges underscore a significant barrier in the field of AI, preventing the development of specialized models and maintaining a dependency on a few large tech corporations. The need for a transformative shift in how data is curated and accessed is evident, similar to the “Linux moment” in software history. Envisioning a global data repository, where anyone could contribute data and access it freely for model training, holds the potential to democratize AI development significantly. Acknowledging the urgency and potential impact of addressing this data accessibility issue, Shashank Yadav was inspired to initiate Fraction AI.
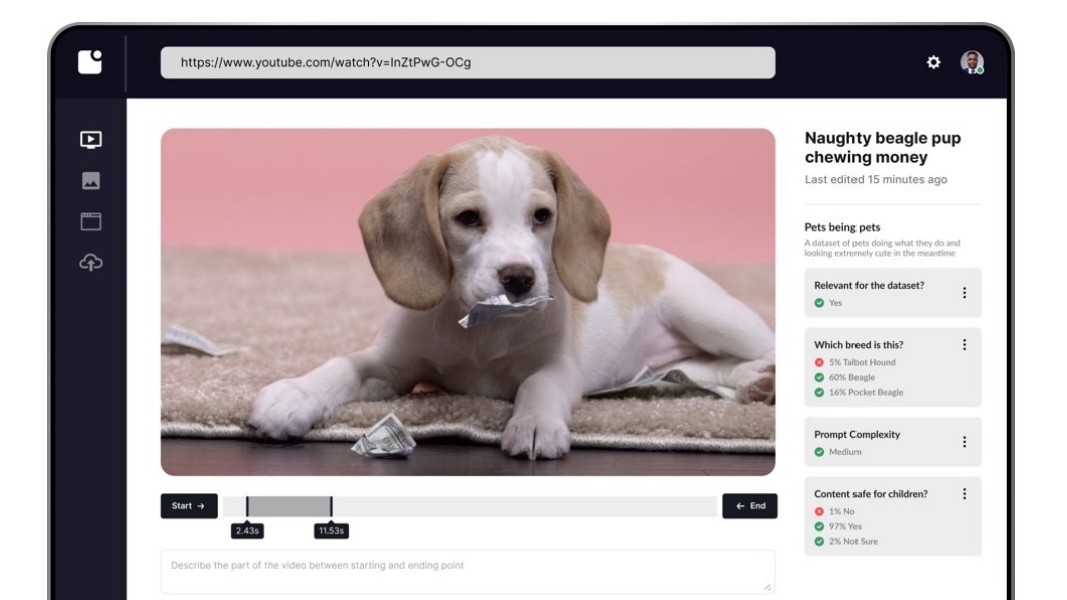
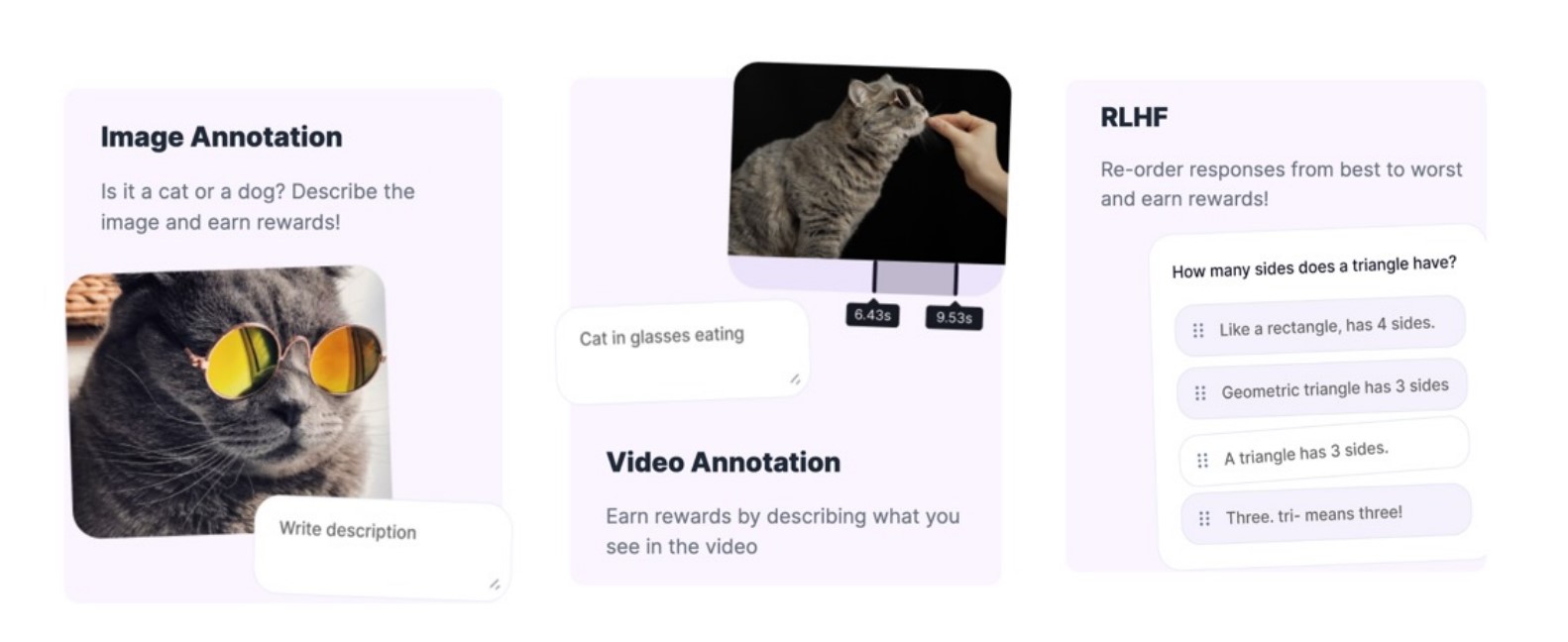
The founding of Fraction AI and early milestones
Shashank Yadav identified Web3 technology as a natural remedy for the prevalent challenges in accessing and utilizing high-quality annotated data. Web3 facilitates trustless participation and establishes decentralized incentive structures, features that are essential for creating a more open and equitable data ecosystem. Moreover, this technology offers a global distribution system that enhances community engagement, providing a level of collaboration and accessibility that far exceeds the capabilities of previous Web2 structures. Recognizing these benefits, Shashank saw Web3 not only as a technological advancement but also as a strategic foundation for pioneering solutions in the AI field.
The journey to founding Fraction AI began when Shashank Yadav was selected to participate in the Nailwal Fellowship, an exclusive program initiated by Sandeep Nailwal, co-founder of Polygon. This program aims to help founders transition from Web2 to Web3 and boasts an acceptance rate of less than one percent. Shashank, among just eight individuals chosen globally, had the extraordinary opportunity to delve into the intricacies of Web3 alongside seasoned industry veterans.
Following the fellowship, Shashank reconnected with his college friend, Rohan Tomar, who was also immersed in a Web3 project. Inspired by their shared insights into Web3’s transformative potential, they co-founded Fraction AI—a decentralized platform where humans and AI agents collaboratively produce the highest quality labeled datasets. The idea quickly took off, and remarkably, within just six months of its inception, Fraction AI achieved $200k in revenue and garnered support from top-tier backers, including Sandeep Nailwal (Polygon), Illia Polosukhin (Near), Shiliang Tang (LedgerPrime), Kartin Wong (ORA Protocol), and many others. Demand for its seed round reached four times oversubscription, signaling strong market approval and investor confidence. Yet, Shashank and Rohan see this as just the beginning of their journey.
They envision Fraction AI evolving into an AI Chain—a robust network where millions of humans and AI agents collaborate. This platform aims to democratize the development of AI, making it possible for anyone to train specialized models, thereby liberating AI from the constraints imposed by government oversight and the monopolistic hold of major tech companies.
Imagine training a model like Stable Diffusion or Midjourney to create images from textual descriptions. This process requires thousands of images and corresponding descriptions. Fraction AI offers a decentralized platform where anyone can contribute images or annotate existing ones. Multiple contributors suggest descriptions for each image, and the most accurate description is selected based on consensus among verifiers. This method ensures the highest quality data and adds the most value to AI models. This approach also extends to other types of datasets, such as text, audio, video, and 3D assets. The decentralized nature of Fraction AI means there is no single entity controlling participation or rewards; everything is driven by the community. Anyone from any part of the world can connect their wallet and join the platform.
The founders of Fraction AI are spearheading a movement to democratize AI development. Their long-term goal is to ensure that the benefits of AI and high-quality data are accessible to all, heralding a new era of innovation and independence in the tech world.

To learn more about the innovations driving blockchain forward – read the full report here.
Related: The Convergence of AI and Blockchain Technology: Overview

%2Fuploads%2Finnovations-blockchain%2Fcover2.jpg&w=3840&q=75)



